Regionlets
is an object detection approach aimed at detecting objects in arbitrary scales,
arbitrary viewpoints, with the capability of deformation and sub-category handling.
It detects objects at their original scale,
i.e. the approach does not resize the image when performing training/testing. Compared to traditional object
detection paradigm, Regionlets model differs in:
Feature histograms are built in variable regions
(vs fixed size cells, 8x8 HOG for example)
Feature extraction regions are normalized to detection windows.
Deformation handling is learned from data.
Learned Regionlets model is lot limited by a fixed scale or aspect ratio.
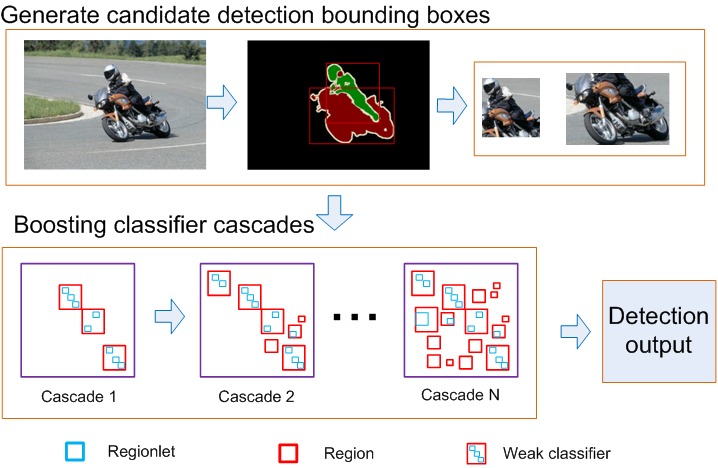
Figure 1 shows the detection framework.
Figure 1. Regionlets detection framework
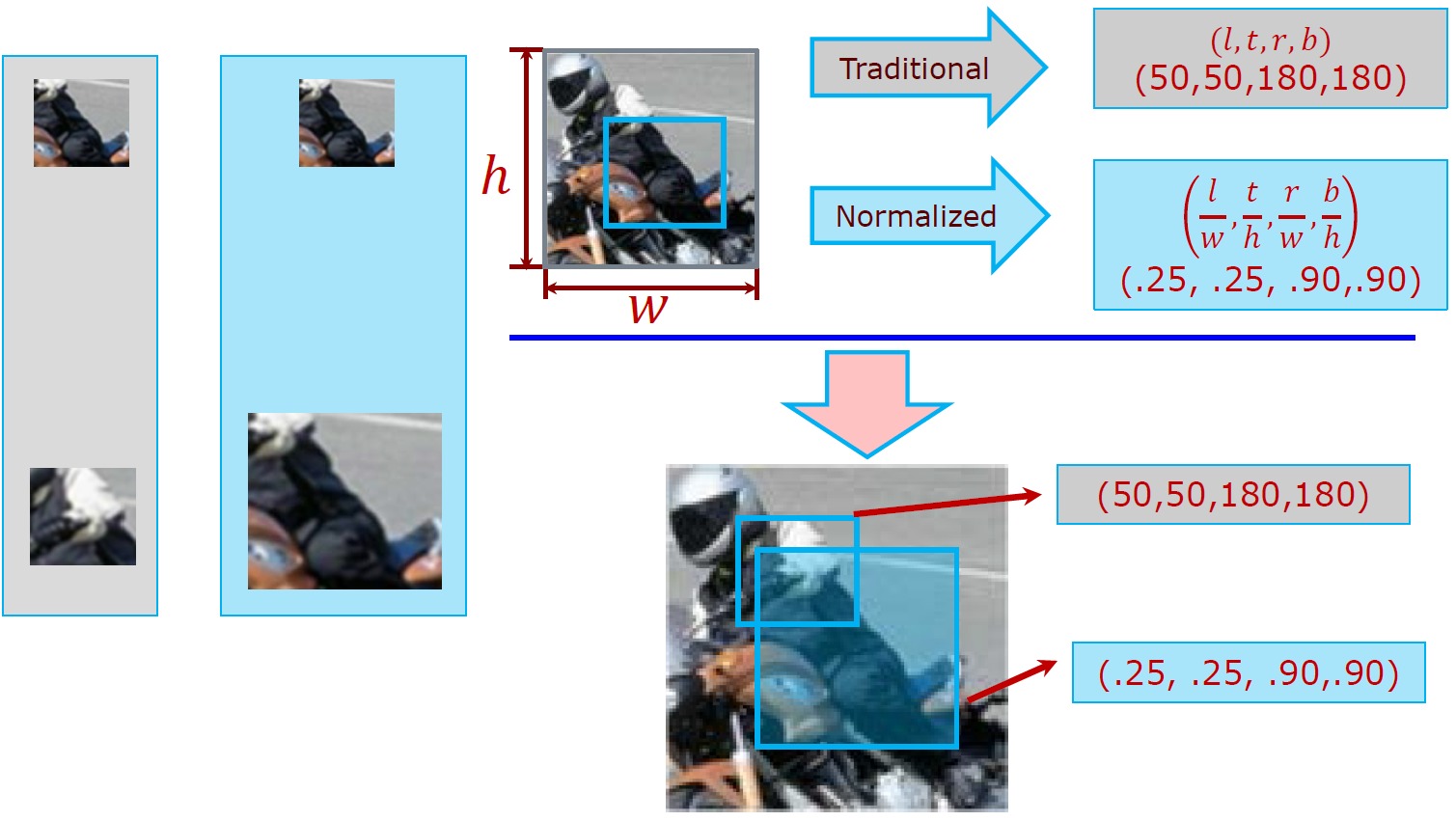
Figure 2 shows the difference of a normalized region and a traditional region
in two examples(the original window and a tranformed one with double resolution).
Figure 2. Normalized feature extraction region
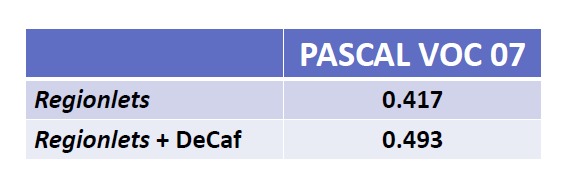
Table 1 shows the detection performance on the PASCAL VOC 2007 dataset.
Table 1. Performance of regionlets on the PASCAL VOC 2007 dataset.